In order to get a better view of your audience or products, an exploratory exercise that can be done is clustering. There are plenty of methods for clustering data, but I will only discuss two of the main ones (to keep the post from turning into a book): hierarchical clustering and k-means (or nearest neighbor) clustering. The method that will be the most efficient for the task at hand will depend on the amount of data available.
Hierarchical Clustering
Hierarchical clustering is best when the amount of data is not too large and when you are unsure of how many clusters you want to make. The principle behind hierarchical clustering is that at every round, the closest two points/groups are clustered. This continues until there is only one group.
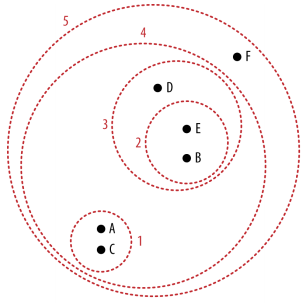
In this example from the book Data Science for Business by Foster Provost and Tom Fawcett, point A and C are grouped together as they are the closest two points out of all of the points there. After that, point E and point B are clustered. During the third round, it gets interesting: point D is clustered with group 2. This happens because the points and groups are considered as a similar type of entity. So, since group 2 and point D had the shortest distance between them, they were clustered into group 3. When clustering groups, you need to decide on the measurement position for the groups. More specifically, when comparing the distances, is the distanced measured to the outer border or to the center of the group? This can make a significant difference in the clustering. It is important to note that at every round, this clustering method calculates the differences between all of the remaining ungrouped points and the remaining groups. As a result, a lot of calculations are needed in order to go through the whole process, which makes this method rather slow. For a small amount of data points though, the analysis will not be slowed down significantly and this remains a viable option.
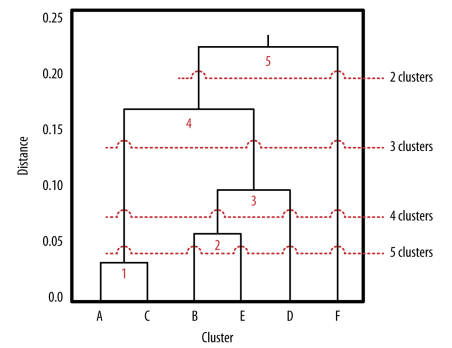
Once all of the groups are made, a dendrogram is created (see right). You start at the bottom with the individual points and cluster going up. The length of the lines specify the differences in distances between the clusters. When you draw a perpendicular line at any point on the dendrogram, the number of clustering lines that it crosses is the number of total clusters that result at that point. The idea here is to draw a line at the point where the clustering lines start to become relatively short. At this point, it means that the distances are relatively small and thus the differences between the points are relatively small. Since the goal of clustering is to create homogeneous groups, the goal of the dendrogram is to signal at how many clusters, the groups are more or less homogeneous. In this example, it would be at around 3 clusters, based on the dendrogram.
K-means Clustering
The other clustering method, k-means or nearest neighbor, has the advantage that it is significantly faster. However, in order to perform a k-means clustering, you must know ahead of time how many clusters you would like to have. The idea behind k-means clustering is that the algorithm will use your desired number of clusters and place that number of centroids on the plane with the points. Then, each point is assigned to the closest centroid. During the next round, the centers of those created groups is recalculated and used as the new centroids. After that, the points are reassigned to the closest centroid. This process repeats until the centroids at the beginning of the step are at the same location at the end of the step (i.e. they did not move). At this point, the algorithm has created the most efficient clusters given the number of clusters needed.
This process may seem complicated and long but it is actually more efficient than the hierarchical clustering since it only calculates the distance between each point and the centroids. On the other hand, in hierarchical clustering, at every step, the distance between every pair of points/groups is calculated, which can become unmanageable with large datasets.
The Best of Both Worlds
At this point, you are probably thinking: well, why not combine both of the methods and get the best of both worlds? This has indeed been done and if you would like to learn more about how these two methods have been combined to form the optimal algorithm, feel free to do some research on “Two Step Clustering”.
Real World Applications
Clustering is a wonderful method to do some exploratory research of our audience or your products. You can determine the different types of clients that your company appeals to, which can in turn help you tailor your products and marketing. Clustering can also determine in what groups your audience places the products. To find this out, you will need to have some of the customers rate all of the products based on their attributes. Then, you can perform multidimensional clustering to determine how your customer base views your products and which products appeal to which segments of your audience.
Where and why have you used clustering in the past?
Hi there! Such a great post, thanks!